Understand how processes and threads differ
Objective
Background
Process
You would have written programs in languages like C++, Java, Python etc. When residing as a file in our computer, these are just text files written in fancy languages.
The magic happens when the program becomes a process i.e. when we run the program. Suddenly, a whole lot of extra things get associated with it like the stack, heap, registers etc.
-
Stack is where temporary data like your function parameters and local variables are stored. When a function is called, the address of the next instruction to be run in the caller method is added to the stack. This is required to resume the caller method from the instruction where it called the function.
-
Heap is memory which is dynamically allocated at run-time.
-
Registers are very small storage for providing quick access to information like the address of the instruction to be run (program counter).
Every individual process gets to have its own memory region. To avoid different processes stepping into each others’ toes, they don’t get direct access to the RAM memory. OS provides processes with a virtual range of memory addresses to use, which the OS maps to the RAM appropriately.
Threads
(Source: cs.uic.edu)
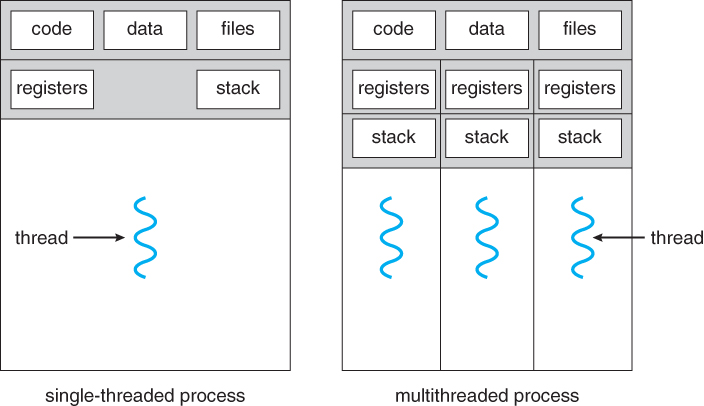
You could live alone in a house or choose to live with your friends. In the latter case, there will be a lot of things all of you will be sharing like the kitchen, TV & electricity bill. There are some things you’ll still need for yourselves like your clothes. Just like that, threads are processing units that can share resources of a process.
Threads of a process can execute different instructions than the other. Hence, they’ll have to keep track of the instruction that each is currently running. This requires dedicated registers. Also, as the stack has to keep track of local variables, function calls & the return address of the caller function, threads require their own stack as well. Other resources like the heap memory, program instructions and open file handles are shared by all the threads.
Primary goals
-
Understand the difference between processes and threads
-
Understand when to use multiple threads
Objective
Understand how processes and threads differ
Background
Process
You would have written programs in languages like C++, Java, Python etc. When residing as a file in our computer, these are just text files written in fancy languages.
The magic happens when the program becomes a process i.e. when we run the program. Suddenly, a whole lot of extra things get associated with it like the stack, heap, registers etc.
-
Stack is where temporary data like your function parameters and local variables are stored. When a function is called, the address of the next instruction to be run in the caller method is added to the stack. This is required to resume the caller method from the instruction where it called the function.
-
Heap is memory which is dynamically allocated at run-time.
-
Registers are very small storage for providing quick access to information like the address of the instruction to be run (program counter).
Every individual process gets to have its own memory region. To avoid different processes stepping into each others’ toes, they don’t get direct access to the RAM memory. OS provides processes with a virtual range of memory addresses to use, which the OS maps to the RAM appropriately.
Threads
(Source: cs.uic.edu)
You could live alone in a house or choose to live with your friends. In the latter case, there will be a lot of things all of you will be sharing like the kitchen, TV & electricity bill. There are some things you’ll still need for yourselves like your clothes. Just like that, threads are processing units that can share resources of a process.
Threads of a process can execute different instructions than the other. Hence, they’ll have to keep track of the instruction that each is currently running. This requires dedicated registers. Also, as the stack has to keep track of local variables, function calls & the return address of the caller function, threads require their own stack as well. Other resources like the heap memory, program instructions and open file handles are shared by all the threads.
Primary goals
-
Understand the difference between processes and threads
-
Understand when to use multiple threads
Getting Started
-
You need access to a Linux machine with sudo access.
-
Have g++ compiler to run simple cpp programs.
g++ SampleProgram.cc -o SampleProgram
./SampleProgram
- For programs using the thread library (has #include
) use
g++ SampleThreadedProgram.cc -o SampleThreadedProgram -pthread -std=c++11
./SampleThreadedProgram
- Understand how to run background process and get its process id.

When you run a program with ‘&’ in the end, it runs as a background job and prints the process id. In the above case, 226285 is the process id.
- You may have to periodically kill these processes you put in the background. Otherwise your system may become slow. If you run
psin the same terminal, you will be able to see the list of all processes. You can then kill the process either usingpkillorkillcommands.


- Understand how to get a list of all the threads of a process - use the
pscommand with -T flag and filter by process id. Here, the entry with same PID & SPID is the parent thread and the other two are child threads

- Understand how to run a program on a specific processor using the
tasksetcommand. The command helps restrict processes to run on single-core even on multi-core machines

What is procfs?
Procfs is a special filesystem in Linux that presents information about processes and other system information in a hierarchical file-like structure. It provides a more convenient and standardized method for dynamically accessing process data held in the kernel. You’ll see it mounted at /proc in your Linux machine.
This command gives the memory layout of your current process denoted by self.
cat /proc/self/maps
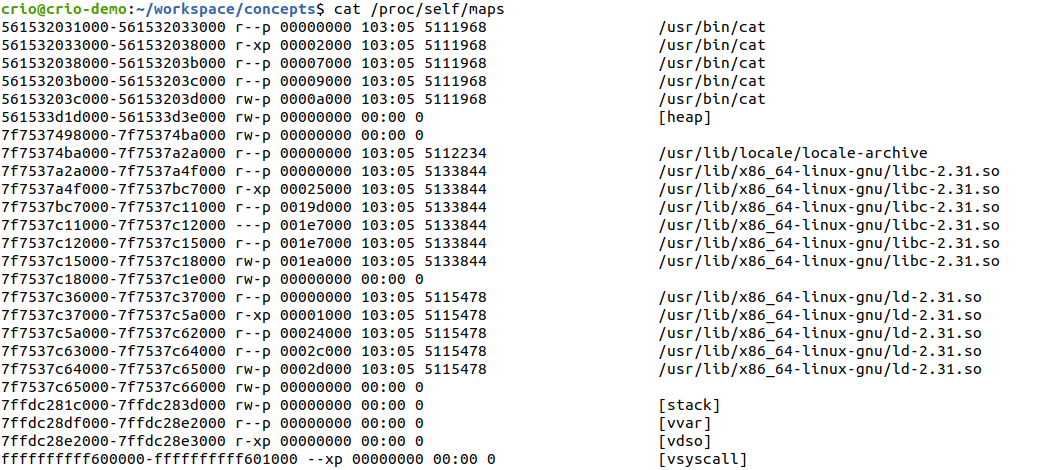
Similarly you can get the memory layout of any process by using
cat /proc/[pid]/maps
Tip
On 32-bit machines, addresses are only 32-bits
A hex digit - 0xf = 1111 -> 4 bits
So 8 digits are there in the address - 0x26a7c010
For 64-bit systems, addresses are 64-bits
0x7fdc81399010 -> Check if they have 16 digits. If not, why?
Memory region for process & threads
We’ll use a program that writes to a particular memory location, 0x10000000. Run two instances of the same program with different values to write. Get the code here.

Ok, they seem to be working independently without overwriting each others’ values. Try out a couple more memory addresses to validate the finding
(Hint: Change the addr variable for setting a different memory location to write to)
Now that we saw processes have their own memory not shared between each other, let’s see the case for threads of the same process. We have two threads - one writes to a memory location and the other keeps on reading it. The program is made available for you here
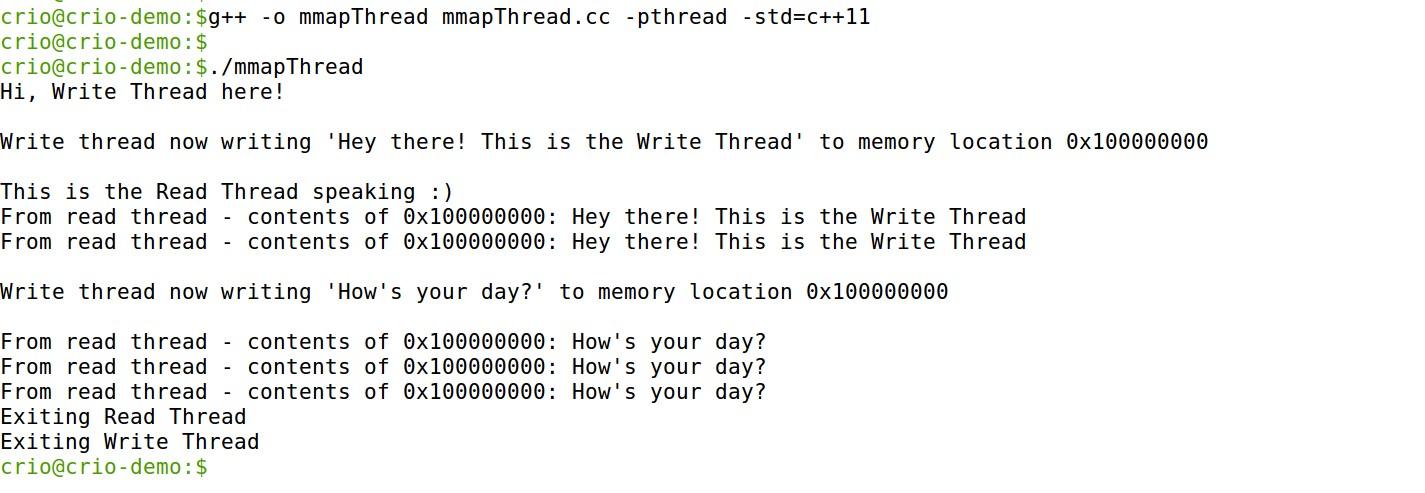
The Write Thread first writes the text ‘Hey there! This is the Write Thread’ to the address 0x10000000 which the Read Thread validates by reading it. Ok, that verifies the threads have access to the same memory location. We’ll go one step further to check that the Read Thread isn’t getting a fixed view of the memory. The Write Thread writes a different text and …, yes, the Read Thread correctly reads that as well confirming that threads do share the memory
Do new threads share the stack of the main thread or are they allocated a new address region each for their stack?
Check the proc-maps output to see how memory allocation for threads is happening. Is it lower?
Use this helper program to check. Utilize proc-maps output to see where the memory address fits in.

Check the proc-maps output to see how memory allocation for threads is happening. Is it lower to a higher address or the other way around or is it random?
References
Curious Cats
-
The memory space of a process is shared by all its threads. As the "private" stack of each thread resides there as well, one thread can read/write from another thread’s stack. Write a program to change the local variable of Thread 1 from Thread 2.
-
If a thread that allocated memory dies, is that memory automatically deallocated? (Modify the time for which the read & write threads sleep in the mmapThread.cc program to make the write thread die first and see if the read thread still reads from the memory)
-
Why would threads require a separate stack for themselves as well as registers? (Think about all that is stored in these)
Threads have to be handled with care!
Processes operate independently of one another. We have a program in which the parent process will spawn a new child process and then try to access an invalid memory location after 15s. Get the code from here. Let’s run it and analyse what happens
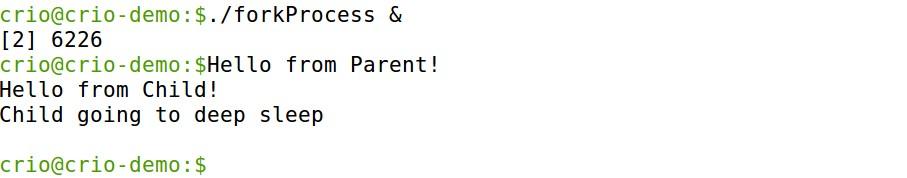
Our parent process’ PID is 6226. Check for processes with the keyword forkProcess, and you can see the child process
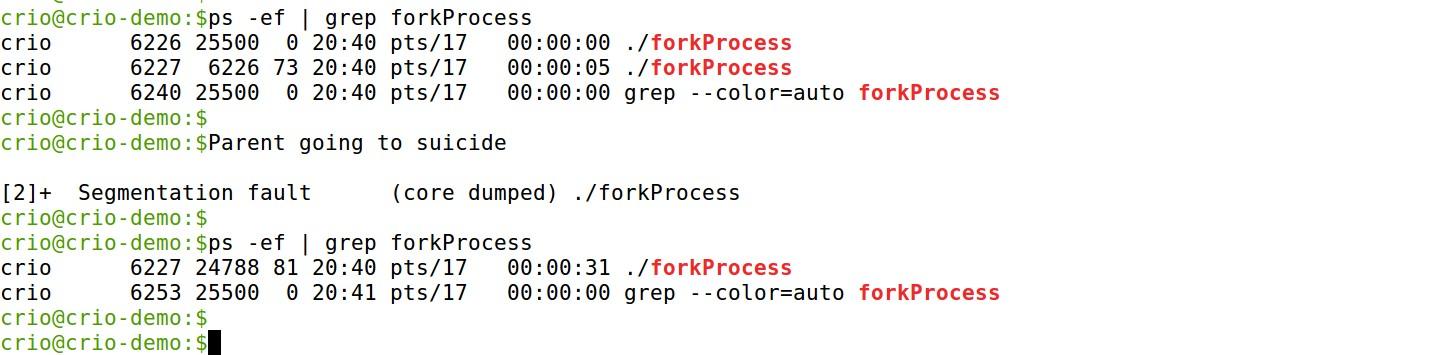
Ok, something happened. It’s showing Segmentation fault (core dumped). This happened as we tried to access an invalid memory location. Now, if we try the ps command again, the child process is still in there, which didn’t get affected by the nefarious actions of its parent process.
Before we move on to check the same for threads, what do you think will happen? Will the suicide thread also become a serial-killer? Why?
We are provided with a program for our purpose. This will create two new threads, one of which is adventurous by nature and like our parent process from the earlier program takes a shot at accessing an invalid memory location. You can get the program here
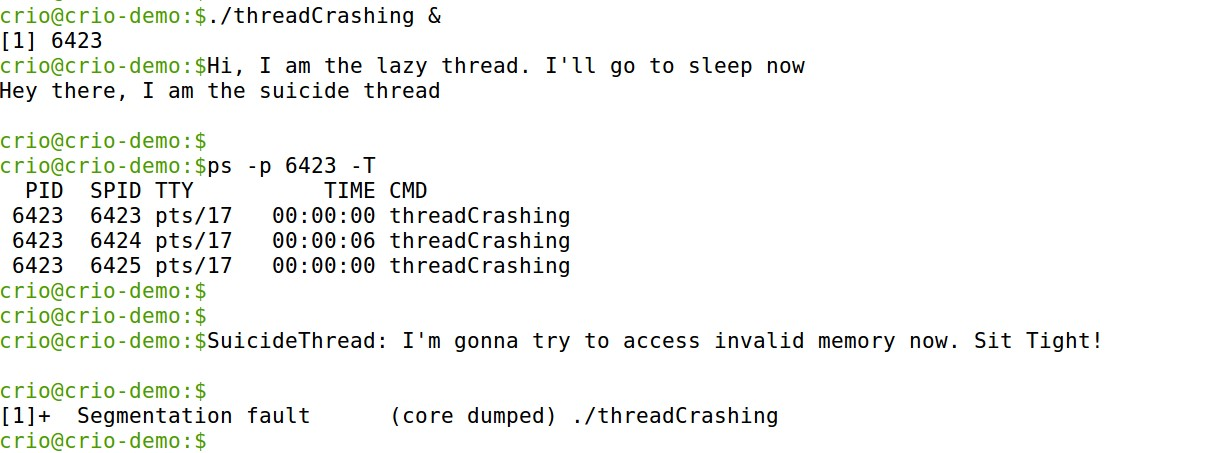
Fancy version of the ps command tells us there are three threads for the process including the parent thread. We get the Segmentation fault as earlier. It’s time for the verdict now. Let’s check what ps has to tell now.

All the processes have been killed (murdered?). This confirms that threads are to be used with utmost care as bugs in one thread can affect every other thread.
Curious Cats
-
We experimented with the thread trying to access an invalid memory location. Would it be always safe with the thread modifying any valid location?
-
Let’s say you have two threads T1 and T2 sharing memory 0xABCD and an integer is stored in that location. Now T1 reads the integer from the address, does some subtraction and stores it back in the same location. T2, in parallel, seems to read the integer from the same location, adds some number to it and stores it back in the same location. Will this always result in the intended output? Hint: Unless you synchronize the access, you will run into race conditions.
Which kind of operations can threads help improve?
What other things, apart from performing numeric operations do processes have to do?
Zoom will have to share video information between the users across the network, programs performing data analysis on huge files will have to read data in chunks and computational units of self-driving cars will need to get data from its sensors.
Operations like these are called I/O operations as they involve Input & Output. While programs that do numeric computations involve more work for the CPU, a fair share of I/O intensive operations involve waiting for the input & output to complete.
Let’s compare how multithreading improves performance for CPU intensive & I/O intensive operations. We’ll restrict the processes to run on a single CPU core.
Get the compute.cc program from here. This performs computation in a loop for n number of times. Run it and note the milliseconds it took to complete.

We’ll now check with the same computation done with 5 threads performing n/5 loops each. Uncomment the lines in compute.cc as instructed.

Cool, we saved 14 seconds. The running time got almost halved.
What do you think will be the case for I/O operations like a network request? Will there be any improvement or will it take even more time? Give it a quick thought before moving ahead.
Our I/O intensive program will run ping commands repeatedly. Here’s the program. Add your favourite web address to ping in the program. Feel free to take a break after setting the single-threaded version to run. It’ll take more than a minute.

Hmm! That was a long run, 80s.
Let’s move on to checking the time taken by splitting the work among 5 threads as earlier.

Were you expecting that? A whopping performance improvement of more than 300%!
This quick experiment helped us see that threads improve performance of I/O intensive operations more than compute intensive operations, even on a single core machine.
Curious Cats
-
Did you ever wonder why even single core machines can leverage threading? Can you explain now based on the above experiment you did?
-
Will compute intensive threads gain more when run on multiple processor cores? How many of these threads will you be able to run in parallel?
-
Try running the above programs with still more threads, play around with it. How does the performance of both the programs vary compared to the earlier case?
-
Can you now benchmark this slightly varied version of the compute intensive program we tried earlier and see if anything stands out? The only difference is the loop not having the power method
Newfound Superpowers
-
Threads and Processes have now been experienced, not just learnt!
-
You can now make wise decisions when it comes to choosing between the two in different situations.
Now you can
Answer the following questions which you might not have been able to before:
-
Explain why creating a thread is light weight whereas creating a process is heavier?
-
Which communication is easier - between two processes or between threads? Think about shared memory.
-
Why should we handle memory access by threads more carefully than by processes?
-
If any of the threads crash, can it take down the whole process? Will this happen between different processes?
-
Irrespective of whether a system is multi-core or not, which type of operations gain the most with threads, CPU intensive or I/O intensive?