This project involves the use of K-Means Clustering to find the best accommodation for students in Bangalore (or any other city of your choice) by classifying accommodation for incoming students on the basis of their preferences on amenities, budget and proximity to the location.
Objective
Project Context
Implementing the project will take you through the daily life of a data science engineer - from data preparation on real-life datasets, to visualising the data and running machine learning algorithms, to presenting the results.
In the fast-moving, effort-intense environment that the average person inhabits, It’s a frequent occurrence that one is too tired to fix oneself a home-cooked meal. And of course, even if one gets home-cooked meals every day, it is not unusual to want to go out for a good meal every once in a while for social/recreational purposes. Either way, it’s a commonly understood idea that regardless of where one lives, the food one eats is an important aspect of the lifestyle one leads.
Now, imagine a scenario where a person has newly moved into a new location. They already have certain preferences, certain tastes. It would save both the student and the food providers a lot of hassle if the student lived close to their preferred outlets. Convenience means better sales, and saved time for the customer.
Food delivery apps aside, managers of restaurant chains and hotels can also leverage this information. For example, if a manager of a restaurant already knows the demographic of his current customers, they’d ideally want to open at a location where this demographic is at its highest concentration, ensuring short commute times to the location and more customers served.If potential hotel locations are being evaluated, a site that caters to a wide variety of tastes would be ideal, since one would want every guest to have something to their liking.
This project is a good start for beginners and a refresher for professionals who have dabbled in python / ML before. The methodology can be applied to any location of one's choosing, so feel free to innovate!
Project Stages
The project consists of the following stages:

High-Level Approach
- Fetch Datasets from the relevant locations (Data Collection)
- Clean the Datasets to prepare them for analysis. (Data Cleaning via Pandas)
- Visualise the data using boxplots. (Using Matplotlib /Seaborn /Pandas)
- Fetch Geolocational Data from the Foursquare API. (REST APIs)
- Use K-Means Clustering to cluster the locations (Using ScikitLearn)
- Present findings on a map. (Using Folium/Seaborn)
The desired end result of this project is something like this:

Applications
K-Means clustering is used in a variety of examples or business cases in real life, like:
- Academic performance (grouping students by their learning rate)
- Diagnostic systems (grouping system faults under various reasons)
- Search engines (grouping search results)
- Wireless sensor networks (Mapping networks)
The FourSquare API data can be used for:
- Building a restaurant review app like Swiggy Zomato etc.
- Supporting a ride sharing service like Uber Pool
Objective
This project involves the use of K-Means Clustering to find the best accommodation for students in Bangalore (or any other city of your choice) by classifying accommodation for incoming students on the basis of their preferences on amenities, budget and proximity to the location.
Project Context
Implementing the project will take you through the daily life of a data science engineer - from data preparation on real-life datasets, to visualising the data and running machine learning algorithms, to presenting the results.
In the fast-moving, effort-intense environment that the average person inhabits, It’s a frequent occurrence that one is too tired to fix oneself a home-cooked meal. And of course, even if one gets home-cooked meals every day, it is not unusual to want to go out for a good meal every once in a while for social/recreational purposes. Either way, it’s a commonly understood idea that regardless of where one lives, the food one eats is an important aspect of the lifestyle one leads.
Now, imagine a scenario where a person has newly moved into a new location. They already have certain preferences, certain tastes. It would save both the student and the food providers a lot of hassle if the student lived close to their preferred outlets. Convenience means better sales, and saved time for the customer.
Food delivery apps aside, managers of restaurant chains and hotels can also leverage this information. For example, if a manager of a restaurant already knows the demographic of his current customers, they’d ideally want to open at a location where this demographic is at its highest concentration, ensuring short commute times to the location and more customers served.If potential hotel locations are being evaluated, a site that caters to a wide variety of tastes would be ideal, since one would want every guest to have something to their liking.
This project is a good start for beginners and a refresher for professionals who have dabbled in python / ML before. The methodology can be applied to any location of one's choosing, so feel free to innovate!
Project Stages
The project consists of the following stages:
High-Level Approach
- Fetch Datasets from the relevant locations (Data Collection)
- Clean the Datasets to prepare them for analysis. (Data Cleaning via Pandas)
- Visualise the data using boxplots. (Using Matplotlib /Seaborn /Pandas)
- Fetch Geolocational Data from the Foursquare API. (REST APIs)
- Use K-Means Clustering to cluster the locations (Using ScikitLearn)
- Present findings on a map. (Using Folium/Seaborn)
The desired end result of this project is something like this:
Applications
K-Means clustering is used in a variety of examples or business cases in real life, like:
- Academic performance (grouping students by their learning rate)
- Diagnostic systems (grouping system faults under various reasons)
- Search engines (grouping search results)
- Wireless sensor networks (Mapping networks)
The FourSquare API data can be used for:
- Building a restaurant review app like Swiggy Zomato etc.
- Supporting a ride sharing service like Uber Pool
Getting Started
We need data to do data analysis! Fetch the data we need and set up your environment before you move on to data analysis.
Requirements
- Head over to this link to get a dataset we'll be using. If you run into "too many requests", here's a drive link.
- Note that you'll need both files, the csv and the document - the document explains the meaning of the CSV values.
- You will need a jupyter notebook installed in your environment.
- Explore the
codebook_foodfile. There are around 70 parameters. Not all of them are relevant. Think carefully about which ones are the most useful. Which ones can be used to quantifiably differentiate students? A good example of this is income. A more qualitative parameter like "How much they like vegetables" on a 1-5 scale might not be as useful. - Extract the most relevant features into a pandas dataframe.
- This process of Extracting the features, (and dealing with different kinds of values as well as NaN values) is known as Data Cleaning.
Expected Outcome
You should have a pandas dataframe with the relevant parameters ready to go for analysis in a jupyter notebook. Something like this will do:

Data Exploration and Visualisation
Now that we have our data, we need to understand it. A good way to do this is by visualising the data via graphs. Graphs help us quickly get a sense of the data, and are a much more user-friendly way of understanding data as compared to reading thousands of rows of data!
A good graph to look at distributed groups is a Boxplot. It can tell us at glance where the population is concentrated, and how the outliers compare to the average object in the group.
Requirements
- To visualise the
food_choicesdataset you created in the previous task, plot a boxplot on the dataframe. - Refer to the
codebook_foodfile to make sense of the Boxplot. Note down the general trends followed by the population that was surveyed as part of the study. - You should be looking at things like how much each person exercises on average (these people will need gyms), whether they are vegetarian / non vegetarian (we should account for both), and income (this affects the lifestyle of the person significantly.)
Bring it On!
Box plots are just one way to visualise your data. Can you think of any other visualisation methods that might aid your analysis?
Expected Outcome
You should have a boxplot of your cleaned dataset, and a list of insights pertaining to the dataset.

Run KMeans Clustering on the data
K Means Clustering will help us group locations based on the amenities located around them. For example, a location with a high amount of shops nearby will be labeled "Amenity Rich" while a location with less amenities will be labeled "Amenity Poor". Similar locations will be grouped (clustered) together. (Check the references for a more formal explanation!)
Run the KMeans Clustering Algorithm and figure out the best value for K, which we will use later.
Note that here we are applying K means first on the dataset of the general population, which will help us organise the population into groups. Further down the line, we will apply K means again on a different dataset.
Requirements
- Run KMeans clustering on the dataset you have. Use trial and error to figure out the best value of K. (Note: The best value of K is where the clusters are clearly demarcated on particular attributes, e.g. income)
- Note the difference in the clusters as you step through different values of K. It might be a good idea to plot boxplots again to see if there's any visible demarcation based on different parameters.
- Once you are settled on a K value, preserve the boxplots and jot down any insights you find. We'll need these later!
Tip
Income is usually a reliable way to differentiate people, as different classes of people tend to have different habits.
Expected Outcome
You should have the optimum K value for the dataset, and the parameters on which the clusters are differentiated.
Get Geolocational Data from Foursquare API
Now that we know the best K value for our population, we need to get geolocational data from the Foursquare API to find these people some accomodation!
Requirements
- Make a free foursquare account and get your API credentials set up. (Note that there are limits on a free account, so be careful about calling the API!)
- Set up your query in such a way that you can check for residential locations in a fixed radius around a point of your choosing. For example, you can pick (13.133521,77.567135) if you want a sample location in Bangalore. Here's how the API response might look:
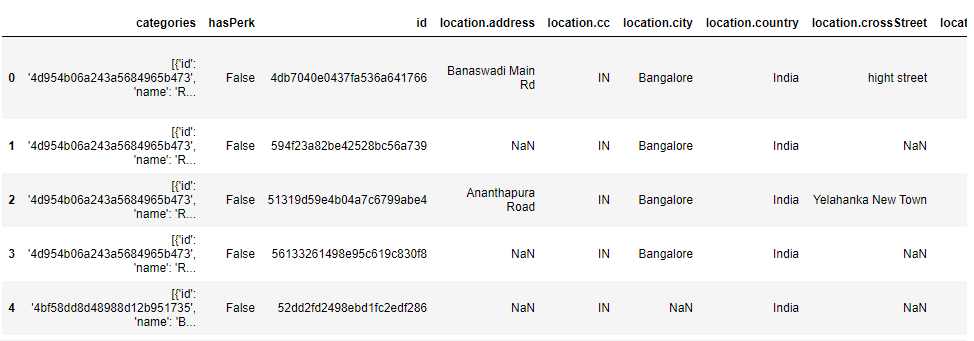
- Hit the endpoint, and parse the response data into a usable dataframe. There is a lot of information you don't need, so apply the same data cleaning principles you used in Task 1 to get a workable dataframe.
- We also need a count of grocery stores, restaurants, gyms etc. around each residential location. Form another query to get all these locations (fixed in a short distance around each residential location) and hit the endpoint again. Here's how this API response might look:
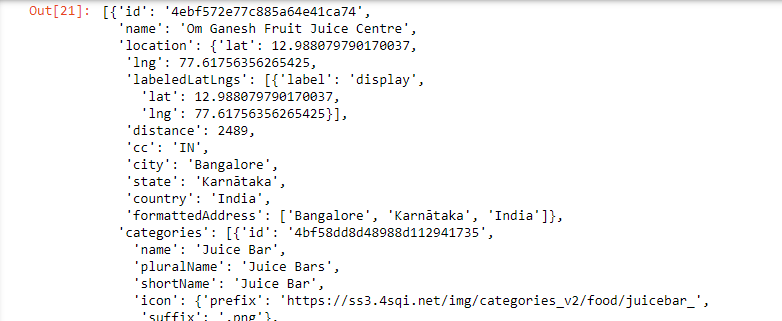
- Clean up the data in the same way as before - drop the irrelevant values, handle the NaN values(if any) and summarise the results into a dataframe. Click here for a refresher if you need it.
Tips
- NaN values are okay, as long as you don't have too many in the dataframe. Pay attention to selecting the parameters you need first, before dealing with other aspects of Data Cleaning.
- You will want to filter locations by distance. A shop 50 km away from your house isn't exactly useful!
Expected Outcome
You should have a dataframe with the locations (in latitude, longitude) format, along with the counts of how many amenities are present around each location.

Plot the clustered locations on a map
Now it's time to run K Means clustering on the data (finally!) and plot the results on a map.
Note that here we are applying K means on the dataset of the locations which we chose, which will help us find the best location for each population group that we found in Task 3.
Requirements
- Run K Means clustering on the dataset you prepared in the previous milestone, with the optimal K value you found.
- Now that you have the results, it's time to visualise them. Using Folium, Plot your results on a map of the world, centered on the location you chose.
- Define a proper colour scheme so the locations are easily differentiated by the cluster number.
Bring it On!
Now that you have the results, try and make sense of them - what sort of person will live in what cluster? Are there any particular criteria/demographics that go well together? Knowing all this will help you present your findings if you were doing a case study as a Data Scientist!
References
Expected Outcome
You should have a map centered on the location you chose, with the locations differentiated by colour scheme. Have a look at the screenshot below for reference.